


Build Deployable Physical AI Models
Eliminate hardware compatibility issues and late-stage compilation failures
Design, optimize, and quantize with PyTorch
Deploy confidently on edge
.svg "pip install embedl-deploy (3)")
AI Deployment Challenges
Python is flexible; hardware is not
Models are complex
- Graph tracing breaks on complex models with dynamic control flow
- Models fail to export reliably
Unsupported operations
- Hardware toolchains have strict operator restrictions, e.g., no ReLU6
- Unsupported operators require manual rewriting of models after design
Hidden graph conversions
- "Black box" compilers convert models unpredictably
- Debugging deployment issues becomes complicated
Quantization pitfalls
- Incorrect quantization breaks operator fusions
- Severe performance bottlenecks due to poor quantization
Embedl Deploy Solution
A Python toolkit that ensures AI models meet hardware constraints by enforcing them in PyTorch
PyTorch Native Workflow
Apply graph rewrites, operator fusion, hardware-aware quantization, and mixed-precision quantization to the PyTorch model before compilation
pip install embedl-deploy
Hardware-restrictions enforced in PyTorch
Compiler constraints and operator fusions enforced during model design or transformed automatically.
from embedl_deploy import transform
from embedl_deploy.tensorrt import TENSORT_PATTERNS
# Apply hardware-aware fusions and conversions
fused = transform(model, TENSORRT_PATTERNS).model
Quantization Optimized
Hardware-aware QDQ placements to ensure best accuracy and performance. Apply post-training quantization (PTQ) or quantization-aware training (QAT) using embedl-deploy with no added dependencies other than PyTorch
from embedl_deploy.quantize import quantize
ptq_model = quantize(
fused,
(example_inputs,),
quant_config,
calibration_loop,
)
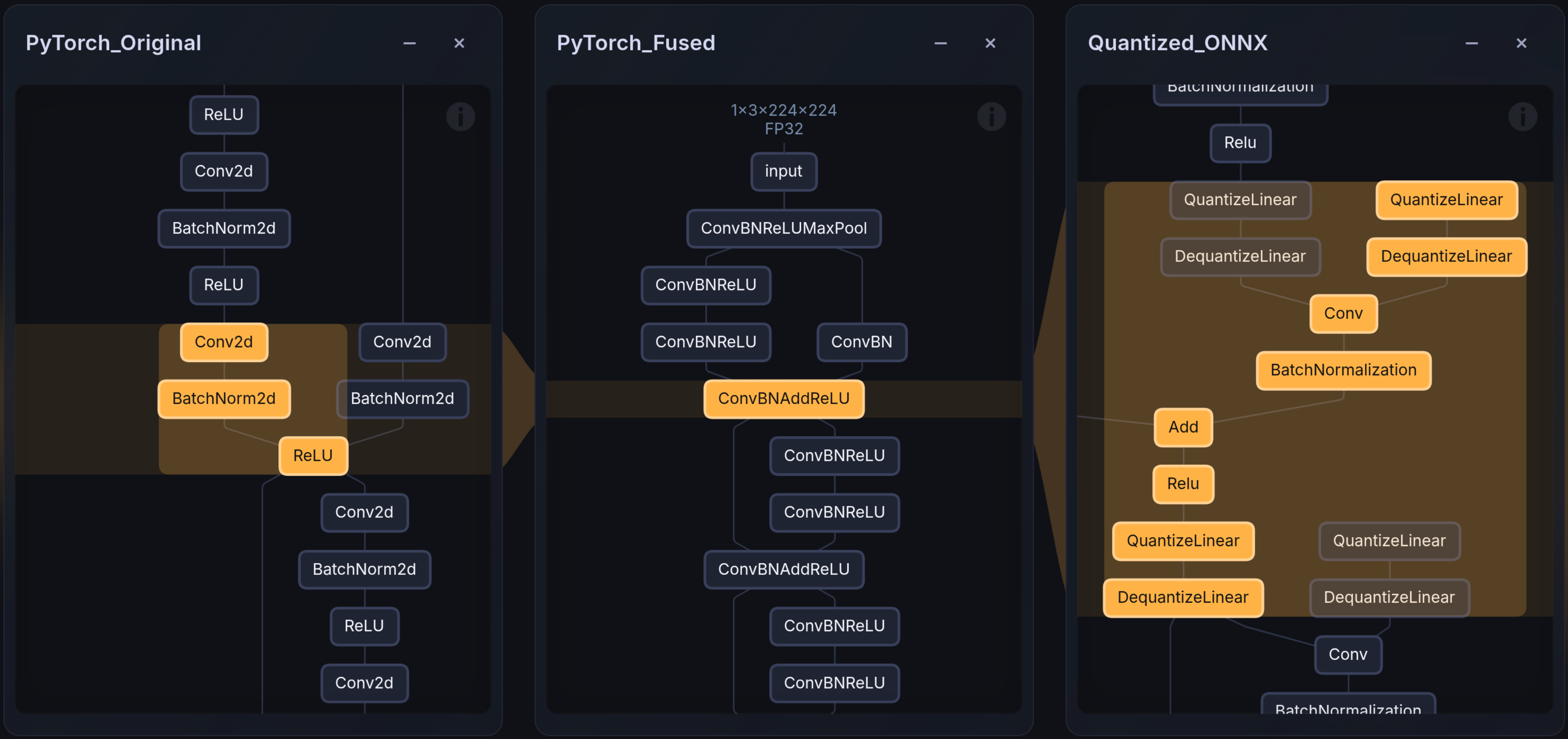
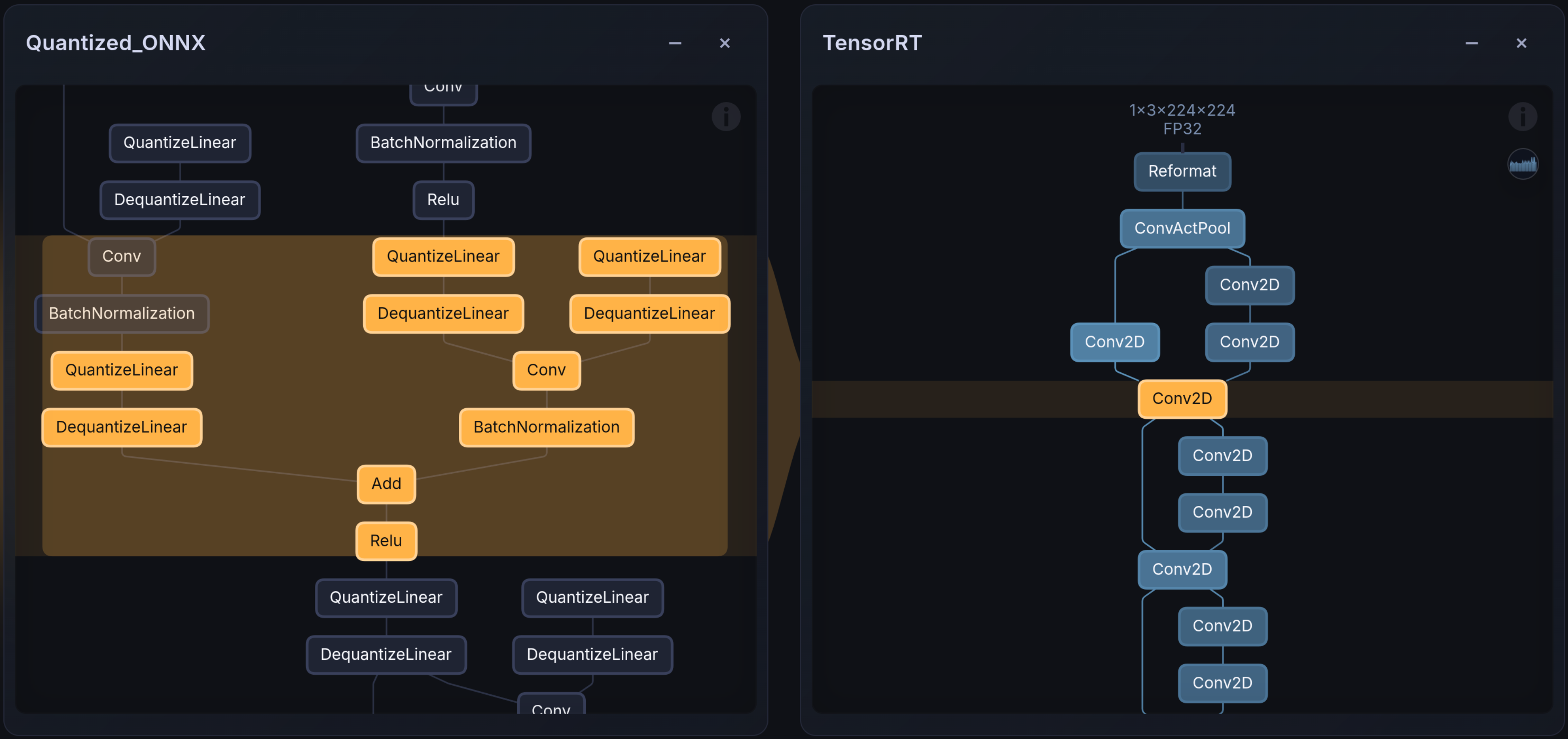
Hardware backend for Edge deployment
Eliminate vendor-specific compilation and quantization errors. What you design and build in PyTorch is what runs on hardware, no late-stage failures and easier debugging.
Automates TensorRT integration by identifying and replacing unsupported operators prior to compilation. Prevents runtime failures and unexpected graph fusions on Jetson and Orin platforms.
Manages TIDL-specific quantization and memory alignment. Prevents silent failures and accuracy drops caused by automatic operator substitution in the TI compiler toolchain.
Get started with Embedl Deploy
Ready to eliminate your model deployment problems?
Check out Embedl Deploy on GitHub
Frequently Asked Questions
Embedl Deploy is a Python package to make AI models deployment-ready for any hardware.
It makes PyTorch models compatible, quantized, and deployable for selected embedded hardware platforms. Embedl Deploy bridges the gap between flexible AI model development in Python and hardware constraints during deployment. Instead of discovering incompatibilities late in the deployment process, you detect and resolve them early in PyTorch.
Embedl Deploy is built for:
- Deep learning engineers designing models
- Edge and embedded developers deploying models
- Engineering managers who need predictable deployment timelines
If your team has struggled with quantization issues, unsupported operators, or opaque compiler behavior, Embedl Deploy is designed for you.
Most deployment failures happen because:
- The model uses unsupported operations
- The compiler silently modifies the graph
- Quantization introduces unexpected accuracy drops
- The runtime behaves differently than PyTorch
Embedl Deploy makes these transformations explicit and traceable before compilation. You can see what changed, compare outputs, and understand why.
It reduces late-stage surprises.
Vendor toolchains compile models. Embedl Deploy prepares models so they compile correctly and behave predictably.
Most vendor tools:
- Apply implicit graph rewrites
- Fuse operations without visibility
- Perform opaque quantization adjustments
- Fail late when unsupported ops are detected
Embedl Deploy moves compatibility and quantization earlier into the PyTorch stage. You get transparency and control before the vendor compiler runs.
We don’t replace vendor compilers — we make them reliable to use.
No.
Embedl Deploy uses existing quantization mechanisms where appropriate. It makes quantization explicit in the model graph and aligns PyTorch behavior with compiled behavior.
It is not a new quantization algorithm.
It is a compatibility and traceability layer that uses best-practices for optimizing deployment.
Embedl Deploy focuses on a limited set of selected hardware backends.
We intentionally support only a small number of platforms per release to ensure robustness and deep compatibility, rather than broad but fragile coverage.
Check the documentation for the currently supported targets.
In many cases, no.
Embedl Deploy provides:
- Operator subsets and patterns for each hardware target (fused torch.nn modules)
- Model transformation utilities
- Explicit quantization integration for all fused patterns and modules
You can either build your model using safe operators from the start, or transform an existing PyTorch model into a compatible version.
The goal is minimal friction, not rewriting architectures from scratch.
Embedl Deploy will detect and surface them early.
Depending on the backend, it may:
- Suggest supported alternatives
- Replace operations with compatible equivalents
- Provide a clear explanation of why compilation would fail
You won’t discover the issue at the final deployment step.
Yes. Using for example the Embedl visualizer, you can easily visualize the graph differences across compilation stages between PyTorch models, ONNX models or compiled graphs parsed from TensorRT layer info files.
Transparency is a core design principle. You can:
- Compare model graphs
- Compare outputs before and after quantization
- Benchmark compiled artifacts against the original PyTorch model
You remain in control of what changed.
No system can guarantee that.
Quantization and compilation always introduce trade-offs. What Embedl Deploy does guarantee is:
- You can measure those trade-offs early
- You can trace where deviations occur
- You can align PyTorch and compiled behavior within defined tolerances
It replaces guesswork with measurable behavior.
No.
Embedl Deploy abstracts the complexity in various toolchains into easily understandable patterns and placement of quantization operations.
Advanced users can add patterns based on a deeper knowledge of their models and toolchains, but basic usage does not require hardware-specific expertise. Embedl does the work and packages the expertise into the product.
Embedl Deploy provides publicly accessible tools and documentation.
Commercial use may require a license depending on the backend and deployment context. Contact us for licensing details.
Yes.
Embedl Deploy produces real compiled artifacts that run on-device. It is not a simulation layer.
For enterprise usage, support and licensing options are available.
Embedl Deploy does not:
- Perform neural architecture search
- Do large-scale retraining or pruning
- Provide custom kernel development
- Replace vendor compilers
It focuses strictly on compatibility, quantization alignment, and deployment reliability.
In a typical supported setup, you can:
- Install the package
- Initialize the backend
- Compile and benchmark a model
in under an hour on a clean machine with a supported device.
That is the bar we hold ourselves to.
You can build internal scripts.
But most teams eventually accumulate:
- Fragile shell pipelines
- Version mismatches
- Hidden quantization assumptions
- Knowledge trapped in one engineer’s head
Embedl Deploy aims to provide a general, tested, reproducible solution rather than a patchwork system.
The difference is not whether deployment works once.
The difference is whether it works reliably across projects.