


While the Transformer architecture has taken the natural language processing (NLP) world by storm – witness the amazing ChatGPT, GPT-4 and related technologies – it has also been recognized that they are monster models with over a trillion parameters(!) resulting in huge energy costs and carbon footprint, see the figure.
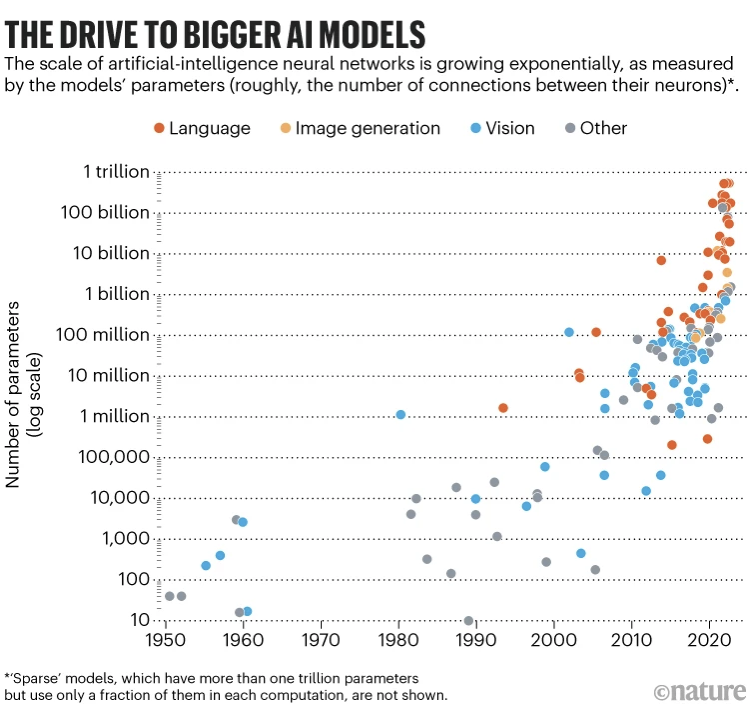
There is thus a pressing need to make Transformer based models more efficient – by reducing their size and optimize them for low resource hardware.
The main mechanism behind the Transformer architecture is the multi-headed attention mechanism (as we explained in the first of this series of posts). Thus, a lot of research has already been devoted to reducing the cost of the attention mechanism. There is a continuously updated survey with a taxonomy of different versions of Transformers optimized in different ways.
The most glaring feature about the attention mechanism is that it scales quadratically with the number of tokens in the sentence. Several attempts have been made to address this issue, from simple engineering hacks like keeping smaller windows to more sophisticated methods to achieve sparsity
- Low rank factorizations of the attention matrix
- K-means clustering of tokens
- Locality sensitive hashing (LSH) techniques
- Orthogonal random features
- Kernel methods
The survey linked above goes over several such methods. While interesting, a huge sticking point is that none of these methods has yet shown its advantage on real world problems beyond the toy examples in those papers. This is a point we return to at the end.
Another way to reduce the size of models is to prune the number of attention heads as in the paper: Are Sixteen Heads Really Better than One? This and other papers use different methods to access the importance of different attention heads and come to the conclusion that some heads are really important and play very specific roles whereas the rest can be safely pruned without affecting the performance significantly.
Finally, it is important to keep in mind that one needs to be very careful in assessing the benefits of compression methods. Simply using FLOPs as a proxy for efficiency is often quite misleading, a point made for Transformers in the paper Efficiency Misnormer. They make the point that simply using a single measure is often misleading, especially when that measure is just parameters count. The actual efficiency is a much more complex matter, and of course it is very closely tied to the underlying hardware platform. This is very much the philosophy of Embedl – our methods take a holistic approach considering several different measures including accuracy, latency and cost and is done in a hardware-aware manner..