


“The Transformer has taken over AI”, says Andrej Karpathy, former Director of AI Research at Tesla, in a recent episode of the popular Lex Fridman podcast. Indeed, it is behind all the dramatic new advances that have made the headlines recently, including the amazing ChatGPT and its successor based on GPT-4.
GPT-4 (Generative Pre-trained Transformer) is the latest in this series of the so-called foundational large language models (LLMs). These are monster models with hundreds of billionsof parameters, trained on large volumes of text (over 45 Gigabytes of data) from the internet. The result has been a system with fluency and competence in generating textual output without parallel in history. All these models are based on the Transformer architecture.
The Transformer architecture provided a surprisingly simple conceptual solution at one stroke to several of problems that had bedeviled natural language processing (NLP) systems in the past. Past solutions based on neural network architectures such as LSTMs and GRUs processed data sequentially, one word at a time, used a fixed sized vector to represent information about arbitrary length sentences and were limited to only looking at a few words earlier in the sequence. The magic used by the Transformer to address all these problems together was the concept of attention.
Attention is a central concept in cognitive science and neuroscience, see this review. There it refers to the fact that while processing information from a visual stimulus, for example, the brain can dynamically focus on different regions. This concept has been borrowed into NLP as illustrated in Figure 1. Suppose we are processing the sentence: “The animal didn’t cross the road because it was too tired”. What does “it” refer to? For a human, it is clear from the context that “it” refers to the animal. For a machine, however, this needs to be made precise. In NLP, the distributional paradigm says: “know a word by the company it keeps” (attributed to Firth 1957). Previous approaches implanted this by keep a fixed size context window around the word of interest. But this and other previous approaches struggled with long range dependencies that went outside a small window as in this example. Attention, as illustrated in the figure is a general solution to this problem: it maintains weights for every other word in the sentence.
In the Transformer approach, a word has three vector representations: a query vector , a key vector and a value vector . The internal representation of the word is given by a sum of all the value vectors weighted by the attention weights given by a similarity function of the query vector of a different word x in the sentence and the current word w. This similarity can be computed in various standard ways e.g. cosine similarity. In matrix form, the transformer self-attention mechanism is summarized as QV. There is also a normalization and a softmax that we’ll skip here, see the details presented nicely by the Illustrated Transformer.
The Transformer then just consists of multiple repeated blocks of this attention mechanism to encode the input. Again, there are more details with several standard tricks of the deepo learning trade such as feed forward layers, normalization layers and skip connections, see the link above to the illustrated transformer.
When decoding the internal representation to generate output, one can again use the attention mechanism: to generate a word, we spread the attention over the full internal representation of the input as well as over the previously generated words.
Figure 1

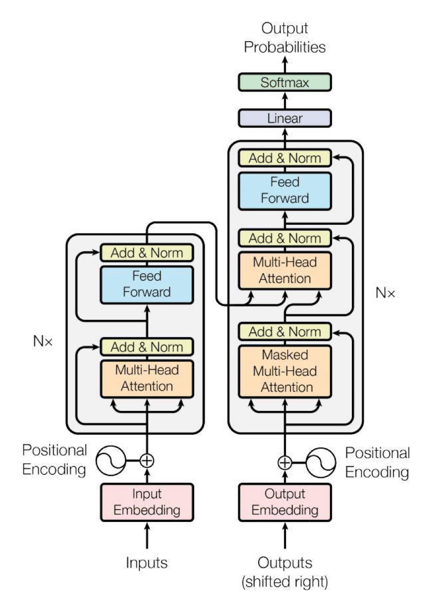
The full Transformer architecture is shown in Figure 2. Since it was introduced in the seminal paper “Attention is all you need” (which has over 72000 citations!), the Transformer has surpassed all previous methods in machine translation and many other tasks, and of course it is the core of the generative LLMs.
Figure 2
Moreover, the attention mechanism is so general, that the basic concept of the Transformer architecture can be applied to many other domains, not only NLP. Indeed, in the podcast cited in the first paragraph above, Andrej Karpathy describes it as a “General-purpose differentiable computer”. In the next post, we’ll see how it can be applied to vision tasks.