


In a previous post, we discussed how the Transformer architecture took the NLP world by storm, and how it’s everywhere now from Bert to ChatGPT and GPT-4. Will they work for vision? This was what a team at Google wondered and tried the simplest thing possible: split the image into patches and treat the patches as if they were words of a sentence This is the Vision Transformer pictured below (image from the original paper):
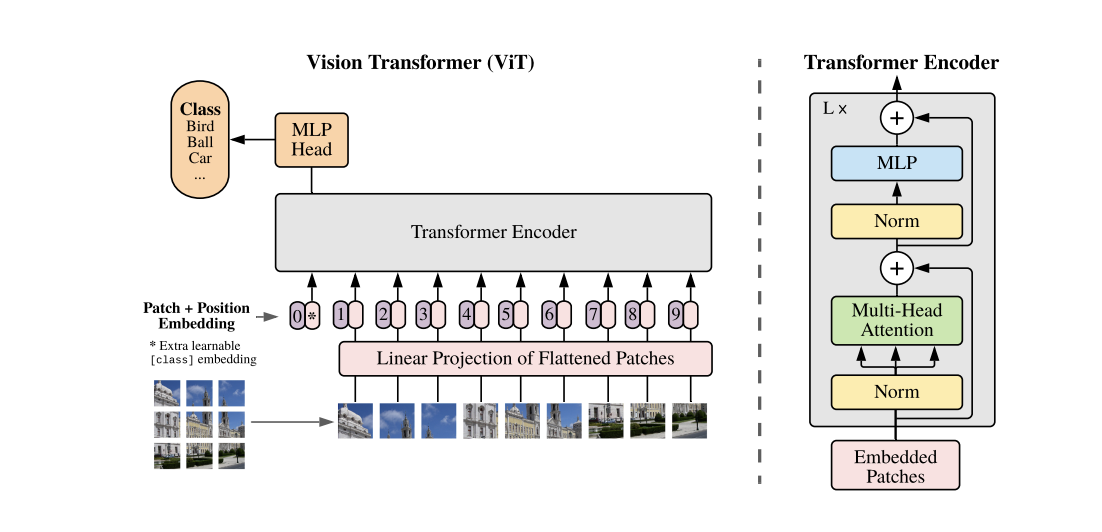
The image is broken up into 16X16 patches and then the patches are fed in as input via a linear projection. Since all two-dimensional information about the image is lost, positional information is tagged on.
Surprisingly, this very simple adaptation leads to results that beat the best CNNs! Provided there is enough data: when trained with the ImageNet-21k dataset, the Vision Transformer beats all previous methods on multiple image recognition benchmarks. Thus, a picture is worth 16X16 words!
What’s going on? How can it beat the carefully crafted CNN architectures that are designed to take into account the translational invariance of natural images? This is another example of Richard Sutton’s bitter lesson of AI “the great power of general purpose methods, of methods that continue to scale with increased computation”. When enough data and compute is available, the Vision Transformer overcomes the inductive bias of the CNN architectures. Andrej Karpathy described the Transformer as a “general purpose differentiable machine” and this is illustrated yet again with the Vision Transformer.
When enough data or compute is not available, then the inductive bias of convolutions in CNNs will have advantage. Also, the Vision Transformer is a large model and is going to be demanding resource-wise. So, to benefit from it on small resource constrained devices, we need to optimize it in a hardware-aware fashion. The architecture is very heterogeneous with different types of components – the central multi-head attention, the MLP layers, the embedding layers etc. When applied with vision, we also have additional parameters to tune such as number of pixels per token and size of positional embedding. Thus there are many opportunities for optimization and this is where Embedl Comes in!
Stay tuned for more insights into transformers in our upcoming post!